국가정보자원관리원 '빅데이터 기반 스마트 치안 구현'
행정안전부 국가정보자원관리원과 경찰청은 28일 치안정책의 패러다임을 전환하고 스마트 치안 구현을 위해 이같은 내용의 빅데이터 분석을 수행 결과를 발표했다.
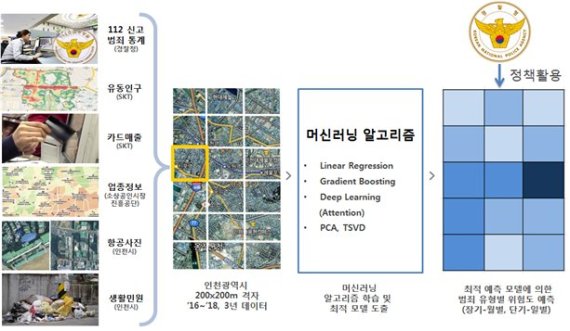
경찰청의 112신고·범죄통계 등 치안데이터를 중심으로 소상공인시장진흥공단의 소상공인 데이터(8만건), 인천시의 항공사진(16.2GB)은 물론 SK텔레콤의 유동인구(530만건)·신용카드 매출정보(521만건) 등 민간과 공공의 다양한 데이터를 결합해 활용했다.
분석 장소는 인천으로 정했다. 송도, 청라 등 신도심과 국제공항, 국가산업단지 등 복합적인 도시 환경이 공존해서다. 인천 지역을 가로 200m, 세로 200m 크기의 2만3000여개 격자로 나눴다. 월(月), 일(日), 2시간 단위로 위험지역을 예측하고 범죄·무질서 발생에 영향을 미치는 주요 환경적 요인을 파악해 ‘매우위험·위험·약간위험·보통·안전’ 등 5단계로 분류했다.
일(日) 단위로 예측모델의 성능을 평가한 결과, 범죄 위험도는 98%의 예측 정확도를 보였다. 범죄가 100건이 발생할 것이라고 예측한 지역에서 98건의 범죄가 발생한 셈이다. 범죄 발생 건수를 바탕으로 예측한 데 비해 정확도가 20.1% 향상됐다.
인공지능 알고리즘 분석 결과 약 2600개 환경적 요인 중 유흥주점 업소의 숫자가 범죄 예측에 가장 중요한 요소로 꼽혔다. 숙박시설의 경우 업소 숫자뿐만 아니라 매출액도 함께 영향을 주는 것으로 나타났고 유동인구의 요일별 편차도 범죄 예측에 중요한 요인으로 판단됐다.
이는 경찰관의 지식과 경험이 담긴 데이터를 인공지능 알고리즘이 학습하면서 요인 간 상관관계를 바탕으로 사람이 미처 발견하기 어려운 환경적 요인을 찾아내 범죄 가능성을 예측한 것이다.
경찰청은 지난 10월14일부터 6주간 범죄 예측 결과를 기반으로 인천시 16개 지역에 경찰관과 순찰차를 집중 배치했다. 그 결과 신고건수는 666건에서 508건으로, 범죄발생건수는 124건에서 112건으로 감소했다.
경찰청은 범죄위험도 예측 모델은 향후 인천 지역을 대상으로 시범 운영 후 전국으로 확대할 계획이다.
김명희 국가정보자원관리원장은 “향후에도 다양한 공공·민간 데이터를 활용하여 국민이 체감할 수 있는 분석과제를 주도적으로 발굴·수행함으로서, 정부 정책에 대한 국민의 신뢰를 얻고 국민의 삶이 개선되도록 노력할 계획”이라고 밝혔다.
eco@fnnews.com 안태호 기자
※ 저작권자 ⓒ 파이낸셜뉴스, 무단전재-재배포 금지